
Universidad
de El Salvador Facultad Multidisciplinaria de Occidente.
Departamento
Ingeniería y Arquitectura.
Catedra:
Bases
de Datos.
Tema:
Guía
para la Creación de un Clúster Postgresql con pgpool-II.
Docente:
Ing.
Alexander Calderón.
Alumnos:
López
Cazún, Marvin Josué.
marvincitojlc@gmail.com
Morales Flores, Rocío Elizabeth.
rociomorales_1a@hotmail.com
Osorio Ramírez, Kevin Manuel.
kevinn_os@hotmail.com
Santa
Ana, 18 de Junio de 2016.
Introducción.
Estudiaremos
los conceptos básicos del clúster en las tecnologías de bases de datos, para
ello veremos específicamente las bases de datos Postgresql y utilizaremos las
tecnologías de pgpool2 para la creación del Clúster.
La
Guía está hecha de forma que sea sencilla de comprender para que podamos crear
y utilizar el Clúster en cuestión de minutos; comenzaremos definiendo ciertos
conceptos, luego instalaremos algunos paquetes que serán necesarios, incluyendo
Postgresql y pgpool2. Después de la instalación de los paquetes configuraremos
unos archivos para poder crear el Clúster luego de lo cual haremos una pequeña
prueba para ver la funcionalidad del Clúster.
Objetivos:
·
Estudiar los
conceptos básicos de las tecnologías Postgresql y pgpool2.
·
Conocer el
concepto de Clúster para Bases de Datos.
·
Aprender las
configuraciones necesarias para hacer un Clúster con las tecnologías
estudiadas.
·
Pequeña prueba
del Clúster.
Conceptos
Básicos.
Clúster:
Este tipo de sistemas se basa en la
unión de varios servidores que trabajan como si se trata de uno solo. En Bases
de Datos de utiliza para dar un alto rendimiento a las Bases de Datos.
Para que el sistema clúster funcione no es necesario que todas las
maquinas dispongan del mismo hardware y sistema operativos. Este tipo de
sistemas debe disponer de una interfaz de manejo de clúster, la cual se
encargue de interactuar con el usuario y los procesos, repartiendo la carga
entre las diferentes maquinas del grupo.
Postgresql:
Es un sistema de gestión de bases de
datos relacional, orientada a objetos y libre, publicado bajo la licencia
PostgresSQL. Cuenta con mas de 15 años de desarrollo activo y además puede
ejecutarse en los principales sistemas operativos: Windows, Linux.
Pgpool2:
Pgpool-II es un middleware que se
encuentra entre los servidores de Postgresql y un cliente de base de datos
Postgresql. Ofrece las siguientes características:
·
Agrupación de Conexiones
·
Replicación
·
Balanceo de Carga
·
Limitar el exceso de conexiones
·
Consultas en paralelo
Desarrollo de
la Guía:
Para el desarrollo de la guía lo haremos en dos computadoras con
sistema operativos Linux/Debian 8.1, los siguientes pasos de instalación,
configuración y pruebas son en una Terminal de dicho sistema operativo.
Utilizaremos
instancias de Amazon ec2.
Paso Uno: Ingresar
a la Consola de la Instancia.
(Para cada Servidor)
Abrimos una terminal normal, una para cada servidor, luego
ejecutamos la siguiente línea:
En la terminal que utilizaremos para el servidor pgsql1:
En la terminal que utilizaremos para el servidor pgsql2:
Nota: Utilizaremos para conectarnos ssh y necesitamos
tener una “llave” en nuestra computadora, la llave se llama key.pem, en nuestro
caso. Deben generar su propia llave con las instancias de amazon que están
utilizando. Además, al darle click derecho a la instancia, en las opciones de menú
que nos aparecen, seleccionamos la opción “Conectar” y nos aparecerá nuestra
cadena de conexión ssh, similar a la que está arriba que ocúpanos nosotros para
conectarnos.
En cada instancia deben tener los puertos abiertos que se
utilizaran, estos son 9999 y 5432.
Durante la guía deben recordar que las direcciones IP son
las que nosotros ocupamos con nuestros servidores, ustedes deben utilizar las
direcciones IP públicas de sus servidores amazon.
A continuación, se muestran las imágenes para abrir los
puertos.



Paso Dos:
Instalación de Paquetes.
(Debemos instalar todos los paquetes en ambos servidores)
1. Algunas
utilidades
$ sudo apt-get install ntp openssl file psmisc sysstat bzip2 unzip
nmap dstat rsync ccze tcpdump pciutils dnsutils host
2. Librerias y
paquetes de Postgresql
$ sudo apt-get install libpq-dev Postgresql-server-dev-9.4 bison
build-essential
$ sudo apt-get install Postgresql-9.4 postgresql-contrib-9.4 postgresql-doc-9.4
uuid libdbd-pg-perl
3. Instalación de
pgpool2
$ sudo apt-get install pgpool2 libpgpool0
Paso Tres:
Configuración de Archivos del Sistema
(En ambos servidores)
Algunas especificaciones:
Servidor 1:
·
Hostname: pgsql1
·
Dirección IP Publica: 52.39.194.30
Servidor 2:
·
Hostname: pgsql2
·
Dirección IP Publica: 52.10.33.58
1. Primero
modificaremos el archivo hostname, para ello ejecutamos el siguiente comando:
$ sudo nano
/etc/hostname
Y modificamos el
nombre.
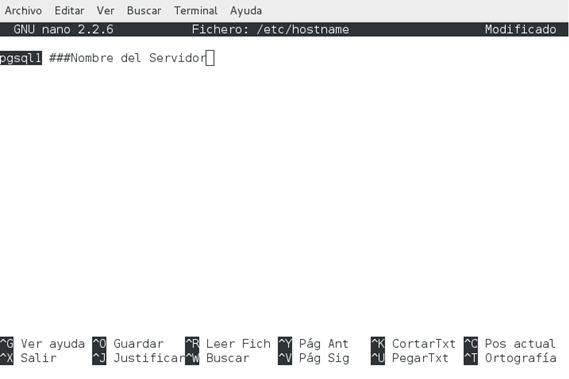
Figura 1. Modificación del archivo hostname.
2.
Ahora
modificaremos el archivo hosts,
$ sudo nano
/etc/hosts
Lo haremos de la siguiente forma:

Figura 2. Modificación del archivo hosts.
Paso Cuatro:
Configuración de los Archivos Postgresql
(En ambos servidores)
Modificaremos dos archivos, estos son pg_hba.conf y postgresql.conf.
1. Para modificar
el primer archivo ejecutamos el siguiente comando:
$ sudo nano
/etc/postgresql/9.4/main/pg_hba.conf
Y solamente agregamos la línea
sombreada en la imagen.
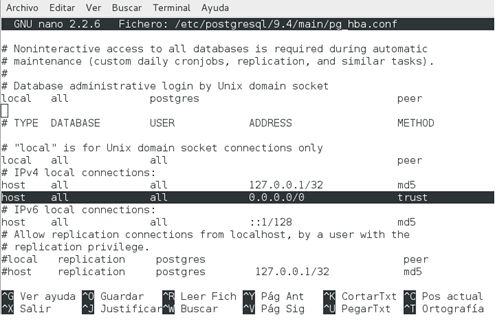
Figura 3. Modificación del archivo pg_hba.conf.
2. Para el
segundo archivo ejecutamos
$ sudo nano
/etc/postgresql/9.4/main/postgresql.conf
Y lo modificamos como muestra la
imagen.

Figura 4. Modificación del archivo Postgresql.conf
Paso Cinco:
Creación de un usuario común.
(En ambos servidores)
Para continuar crearemos un usuario en ambos servidores, llamaremos
al usuario pgpool2 y lo crearemos siguiendo los pasos que están a continuación:
1. Debemos
logearnos como usuario postgres, este es un usuario creado por defecto al
instalar Postgresql.
$ sudo su – postgres
2. Ya logeados
crearemos el nuevo usuario y también le daremos permisos de súper usuario.
$ createuser --superuser pgpool2 password 'contraseña'
Luego de crear el usuario pgpool2 nos salimos del usuario porstgres,
para regresar al usuario normal de nuestra terminal:
$ exit
Paso Seis:
Configuración de los Archivos de Pgpool2
(En Ambos Servidores)
Para poder editarlo ejecutaremos el siguiente comando:
$ sudo nano /etc/pgpool2/pgpool.conf
Mostramos la siguiente lista de directivas, estas serán las que
modificaremos, debemos buscarlas en el archivo que acabamos de abrir,
descomentarlas y cambiarles el valor, de ser necesario.
listen_addresses = ‘*’
port = 9999
backend_hostname0 = ‘pgsql1’
backend_port0 = 5432
backend_weight0 = 1
backend_hostname1= ‘pgsql2’
backend_port1 = 5432
backend_weight1 = 1
replication_mode = on
replicate_select = on
load_balance_mode = on
pgpool2_hostname = ‘pgsql1’ ##### Aquí va
el nombre del nodo donde estamos configurando el archivo.
Paso Siete:
Reiniciamos Servicios.
Ya con los archivos de Postgresql y pgpool2 configurados
reiniciaremos los servicios.
$ sudo service postgresql restart
$ sudo service pgpool2 restart
Ahora ya estamos listos para hacer la prueba.
Paso Ocho:
Prueba del Clúster.
Para realizar la prueba del clúster realizamos los siguientes pasos
(Recordar utilizar las direcciones IP de sus servidores):
1. Debemos
restaurar la Base de Datos. Para ello creamos una base de datos en cualquier
Servidor (en el ejemplo es en el servidor pgsql1) de esta forma:
$ sudo createdb -h pgsql1 -p
9999 -U pgpool2 BaseVentas
2. Necesitamos
tener en nuestro servidor amazon el script que vamos a restaurar, para ello lo
enviamos por medio de ssh con el siguiente comando:
$ sudo scp -i Documentos/key.pem
Documentos/DB_Ventas.backup admin@ec2-52-39-194-30.us-west-2.compute.amazonaws.com:/home/admin
3. Ahora
Restauramos nuestra Base “Mini Tienda” en la base creada en anteriormente.
$ sudo pg_restore -i -h pgsql1 -p
9999 -U pgpool2 -d BaseVentas -v "home/admin/DB_Ventas.backup"
4. Ya con la Base Restaurada entramos para hacer las consultas:
$ sudo psql –U pgpool2 –W –h 52.39.194.30
BasesVentas
5.
Ahora ya podemos ejecutar unas
consultas:
$ INSERT INTO producto(codigoproducto,nombre,precio) VALUES(‘1’,’Memoria
USB’,5.33);
$ SELECT * FROM producto;
$UPDATE producto SET nombre = ‘Memoria USB 4GB’ WHERE codigoproducto
= ‘1’;
$ SELECT * FROM producto;
El Script que utilizamos es el siguiente:
--
-- PostgreSQL database dump
--
-- Dumped from database version 9.4.6
-- Dumped by pg_dump version 9.4.6
-- Started on 2016-05-03 17:04:23 CST
SET statement_timeout = 0;
SET lock_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SET check_function_bodies = false;
SET client_min_messages = warning;
--
-- TOC entry 1 (class 3079 OID 11861)
-- Name: plpgsql; Type: EXTENSION; Schema: -; Owner:
--
CREATE EXTENSION IF NOT EXISTS plpgsql WITH SCHEMA pg_catalog;
--
-- TOC entry 2018 (class 0 OID 0)
-- Dependencies: 1
-- Name: EXTENSION plpgsql; Type: COMMENT; Schema: -; Owner:
--
COMMENT ON EXTENSION plpgsql IS 'PL/pgSQL procedural language';
SET search_path = public, pg_catalog;
SET default_tablespace = '';
SET default_with_oids = false;
--
-- TOC entry 173 (class 1259 OID 16416)
-- Name: DetalleVenta; Type: TABLE; Schema: public; Owner:
bases; Tablespace:
--
CREATE TABLE "detalleventa" (
"codigoproducto"
character varying(20) NOT NULL,
"codigoventa"
integer NOT NULL,
"cantidad"
integer
);
ALTER TABLE "detalleventa" OWNER TO bases;
--
-- TOC entry 174 (class 1259 OID 16419)
-- Name: Producto; Type: TABLE; Schema: public; Owner: bases;
Tablespace:
--
CREATE TABLE "producto" (
"codigoproducto"
character varying(20) NOT NULL,
"nombre"
character varying(100) NOT NULL,
"precio"
money
);
ALTER TABLE "producto" OWNER TO bases;
--
-- TOC entry 175 (class 1259 OID 16422)
-- Name: Venta; Type: TABLE; Schema: public; Owner: bases;
Tablespace:
--
CREATE TABLE "venta" (
"codigoventa"
integer NOT NULL,
"fecha"
timestamp without time zone,
"total"
money
);
ALTER TABLE "venta" OWNER TO bases;
--
-- TOC entry 2008 (class 0 OID 16416)
-- Dependencies: 173
-- Data for Name: DetalleVenta; Type: TABLE DATA; Schema:
public; Owner: bases
--
COPY "detalleVenta" ("codigoproducto",
"codigoventa", "cantidad") FROM stdin;
\.
--
-- TOC entry 2009 (class 0 OID 16419)
-- Dependencies: 174
-- Data for Name: producto; Type: TABLE DATA; Schema: public;
Owner: bases
--
COPY "producto" ("codigoproducto",
"nombre", "precio") FROM stdin;
\.
--
-- TOC entry 2010 (class 0 OID 16422)
-- Dependencies: 175
-- Data for Name: venta; Type: TABLE DATA; Schema: public;
Owner: bases
--
COPY "venta" ("codigoventa",
"fecha", "total") FROM stdin;
\.
--
-- TOC entry 1894 (class 2606 OID 16426)
-- Name: PK_codigoproducto; Type: CONSTRAINT; Schema: public;
Owner: bases; Tablespace:
--
ALTER TABLE ONLY "producto"
ADD CONSTRAINT
"PK_codigoproducto" PRIMARY KEY ("codigoproducto");
--
-- TOC entry 1896 (class 2606 OID 16428)
-- Name: PK_codigoventa; Type: CONSTRAINT; Schema: public;
Owner: bases; Tablespace:
--
ALTER TABLE ONLY "venta"
ADD CONSTRAINT
"PK_codigoventa" PRIMARY KEY ("codigoventa");
--
-- TOC entry 1892 (class 2606 OID 16430)
-- Name: Pk_codigoproducto_codigoventa; Type: CONSTRAINT;
Schema: public; Owner: bases; Tablespace:
--
ALTER TABLE ONLY "detalleventa"
ADD CONSTRAINT
"Pk_codigoproducto_codigoventa" PRIMARY KEY
("codigoproducto", "codigoventa");
--
-- TOC entry 1897 (class 2606 OID 16431)
-- Name: FK_codigoproducto; Type: FK CONSTRAINT; Schema: public;
Owner: bases
--
ALTER TABLE ONLY "detalleventa"
ADD CONSTRAINT
"FK_codigoproducto" FOREIGN KEY ("codigoproducto")
REFERENCES "producto"("codigoproducto");
--
-- TOC entry 1898 (class 2606 OID 16436)
-- Name: FK_codigoventa; Type: FK CONSTRAINT; Schema: public;
Owner: bases
--
ALTER TABLE ONLY "detalleventa"
ADD CONSTRAINT
"FK_codigoventa" FOREIGN KEY ("codigoventa") REFERENCES
"Venta"("codigoventa");
--
-- TOC entry 2017 (class 0 OID 0)
-- Dependencies: 7
-- Name: public; Type: ACL; Schema: -; Owner: postgres
--
REVOKE ALL ON SCHEMA public FROM PUBLIC;
REVOKE ALL ON SCHEMA public FROM postgres;
GRANT ALL ON SCHEMA public TO postgres;
GRANT ALL ON SCHEMA public TO PUBLIC;
-- Completed on 2016-05-03 17:04:23 CST
--
-- PostgreSQL database dump complete
--
No hay comentarios:
Publicar un comentario