
UNIVERSIDAD DE EL SALVADOR
FACULTAD MULTIDISCIPLINARIA DE
OCCIDENTE
DEPARTAMENTO DE INGENIERIA
BASES DE DATOS
ING. ALEXANDER CALDERON PERAZA

Clúster
con Pgpool-II
Desarrollado
por:
Argueta
Campos, Silvia Yessenia
Garcia
Cardona, David Alberto
Gomez,
Benjamin
Ramirez
Reyes, Heysel Yanira
Objetivos:
- Aprender los conceptos basicos del manejo de un Clúster con PostgreSQL y Pgpool-II en Linux .
- Comprender como funciona un Clúster .
- Configurar los equipos necesarios para crear un escenario demostrativo y verificar el uso de un cluster haciendo replicacion de bases de datos con sentencias SQL.
Conceptos:
CLUSTER
Es una coleccion de componentes que se unen y trabajan como un solo
componente para proveer alta disponibilidad. Cuando se habla de
Cluster de bases de datos hace referencia a una arquitectura en la
que se cuenta con varios equipos con parte de los datos del usuario
trabajando como uno solo en un sistema. Su arquitectura viene
definida por la manera en que se almacenan los datos en cada nodo.
POSTGRESQL
Es un Sistema de gestion de bases de datos objeto-relacional,
distribuido bajo licencia BSD y con su codigo fuente libre. Es el
sistema de gestion de bases de datos de codigo abierto mas potente,
utiliza un modelo cliente-servidor y usa multiprocesos en vez de
multihilos para garantizar la estabilidad del sistema. Un fallo en
uno de los procesos no afecta el resto y el sistema continua
funcionando.
PGPOOL-II
Es un middleware que se encuentra entre los servidores de PostgreSQL
y un cliente de bases de datos PosgreSQL. Ofrece las siguientes
caracteristicas:
- Agrupacion de Conexiones
Pgpool-II mantiene las conexiones establecidas a los servidores
PostgreSQL y los reutiliza cada vez que una nueva conexion con las
mismas propiedades entra en juego reduce la sobrecarga de la
conexion, y mejora el rendimiento global del sistema.
- Replicacion
Puede gestionar multiples servidores PostgreSQL, la activacion de la
funcion de la replicacion hace que sea posible la cracion de una
copia de seguridad en tiempo real en dos o mas grupos PostgreSQL de
manera que el servicio pueda continuar sin interrupcion si uno de
esos grupos falla.
- Balanceo de Carga
Si se replica una base de datos la realizacion de una consulta SELECT
en cualquier servidor devolvera el mismo resultado. Pgpool-II se
aprovecha de la funcion de replicacion con el fin de reducir la carga
en cada servidor. Lo hace mediante la distribucion de las consultas
SELECT entre los servidores disponibles mejorando el rendimiento
golbal del sistema. El equilibrio de carga funciona mejor en un
escenario donde hay una gran cantidad de usuarios que ejecutan muchas
consultas de solo lectura al mismo tiempo.
- Limitar el acceso de conexiones
Hay un limite en el numero maximo de conexiones simultaneas con
PostgreSQL y nuevas conexiones son rechazadas cuando se alcanza este
numero. Al aumentar este numero maximo de conexiones aumenta el
consumo de recursos y tiene un impacto negativo en el rendimiento
general del sistema. Pgpool-II tambien tiene un limite en el numero
maximo de conexiones pero las conexiones adicionales se pondran en
otra cola en lugar de devolver un error de inmediato.
- Consulta en paralelo
Los datos se puede dividir entra vvarios servidores, por lo que una
consulta se puede ejecurat en todos los servidores al mismo tiempo
reduciendo el tiempo e ejecucion total. La consulta paralela es la
que funciona mejor en la busqueda de datos a gran escala.
Requerimientos:
- 2 PC'S con sistema operativo linux (debian)
- Un Cable de red
Desarollo:
- INSTALACION DE PAQUETES Y UTILIDADES
1.- Utilidad para
la gestion del cluster
# apt-get install ntp openssl
file psmisc sysstat bzip2 unzip nmap dstat rsync wget ccze tcpdump
pciutils dnsutils host
2.- Se configuraran 2 archivos de debian para hacer refrencia a host
y no a direcciones IP.
# nano /etc/hostname
Cambiar
el nombre de host a pgsql1
en
el host uno y pgsql2
en
el host dos.
# nano /etc/hosts
En este archivo se agregan los nombres de ambos host y sus
respectivas direcciones IP.

- INSTALANDO Y CONFIGURANDO POSTGRESQL
1.- Esta configuracion se hara en ambos nodos, primero hay que
loguearse como root.
2.- Instalar las cabeceras de la librerias de PostgreSQL, el paquete
de desarrollo de PostgreSQL y las utilidades de compilacion de GNU.
# apt-get install libpq-dev
postgresql-server-dev-9.1 bison build-essential
3.- Ahora se debe instalar PostgreSQL en ambos nodos del cluster.
# apt-get install postgresql-9.1
postgresql-contrib-9.1 postgresql-doc-9.1 uuid libdbd-pg-perl
4.- Instalar pgpool-II en el nodo pgsql1.
# apt-get install pgpool2
libpgpool0
5.- Comenzamos la configuracion de PostgreSQL, nos logueamos como
usuario postgres y añadimos el usuario de la base de datos(rol)
pgpool2 sin contraseña.
# su – postgres
# createuser -s pgpool2
Creara un usuario con rol de super usuario.
6.- Editamos ahora el siguiente fichero:
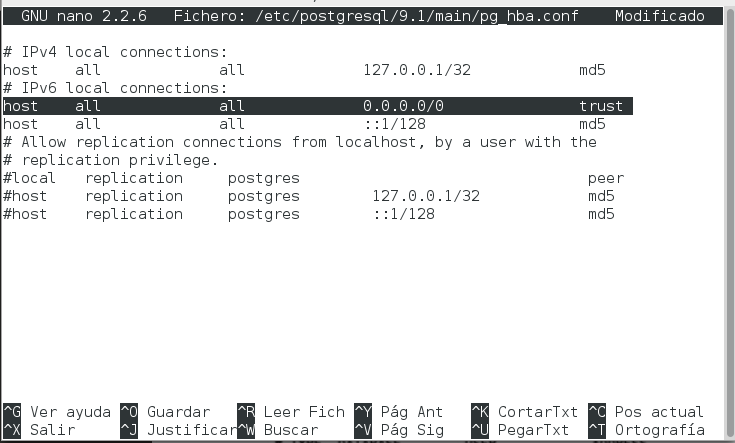
# nano /etc/postgresql/9.1/main/pg_hba.conf
En este fichero se deben agregar los accesos para todos los usuarios
desde cualquier direccion IP. (Se hace de esta forma por conocimiento
general pero para la practica solo se deberia agregar para el
usuario pgpool2 desde la direccion en donde esta instalado.) El
fichero quedara de la siguiente manera:
7.- Ahora debemos indicar a PostgreSQL que escuche en todas las
interfaces ya que por defecto solo lo hace en el localhost editando
el siguiente fichero:
# nano
/etc/postgresql/9.1/main/postgresql.conf
Se debe cambiar la siguiente directiva:
listen_addresses =
'*'
También lo podemos restringir a que solo escuche peticiones de la
direccion IP proveniente de donde esta instalado pgpool-II.

8.- Reinciamos PostgreSQL para activar los cambios
# service
postgresql restar
- CONFIGURANDO PGPOOL-II
Esta configuracion solo la haremos en el host pgsql1.
1.- Editaremos el archivo siguiente:
# nano
/etc/pgpool2/pgpool.conf
Se configuraran los siguientes parametros: Pool de Conexion,
Replicacion y Balanceo de Carga. A continuacion se muestran las
directivas que se modificaran las demas las dejamos como estan.
listen_addresses
= '*'
port
= 9999
backend_hostname0
= 'pgsql1'
backend_port0
= '5432'
backend_weight0
= 1
replication_mode
= true
load_balance_mode
= true
replicate_select
= true
pgpool2_hostname
= 'pgsql1'
2.- Para arrancar pgpool-II se hace con el siguiente comando (start o
restart):
#
service pgpool2 start
3.- Si queremos arrancar pgpoo-II en modo de depuracion primero lo
detendremos con el comando “service pgpool2 stop” y
lo arrancaremos en modo debug de la siguiente manera:
#
pgpool -n -d -f /etc/pgpool2/pgpool.conf
4.- En otra pestaña de la terminal probaremos conectarnos a traves
de pgpool-II utilizando el siguiente comando:
#
psql -h pgsql1 -p 9999 -U pgpool2 -d postgres
El significado del comando anterior es el siguiente:
-h es el nombre de host al que nos vamos a conectar y en donde esta
instalado pgpool-II
-p es el puntero que definimos en el archivo /etc/pgpool2/pgpool.conf
-U es el usuario que creamos en los dos nodos del cluster
-d es la base de datos a la que nos vamos a conectar
Si todo va bien podemos ver que en la terminal nos muestra lo
siguiente:
postgres=#
Indica que hemos logrado la conexión a traves de pgpool-II
- PRUEBAS DE REPLICACION
1.- Primero creamos una base de datos de la siguiente manera:
#
createdb -h pgsql1 -p 9999 -U pgpool2 uesdatabase
2.- Si nos logueamos como usuario postgres en los dos nodos del
cluster (su -postgres) y ejecutamos el siguiente comando para
visualizar las bases de datos nos debe mostrar en cada nodo la base
de datos que creamos en el paso anterior:
$
psql -1
El resutado sera:

No hay comentarios:
Publicar un comentario