
PostgreSQL Cluster con DRBD y Heartbeat
Autores: Ana Herrera,
Byron Guerrero, David Sandoval.
Algunos Conceptos:
- PostgreSQL
Es un SGBD relacional orientado a objetos y libre, publicado bajo la licencia BSD. PostgreSQL es un potente sistema de base de datos objeto-relacional de código abierto. Cuenta con más de 15 años de desarrollo activo y una arquitectura probada que se ha ganado una sólida reputación de fiabilidad e integridad de datos.
- DRBD
Distributed Replicated Block Device es un sistema de almacenamiento distribuido para plataformas basadas en linux. Consiste de un modulo de kernel, herramientas para manejar los discos y una serie de scripts, que son usados normalmente en cluster de alta disponibilidad, es similar a un RAID, pero corre bajo la Red.
Posee tres tipos de replicación:
Protocol A: Protocolo de replicación asíncrona.
Protocol B: Protocolo de replicación síncrona de memoria
Protocol C: Protocolo de replicación síncrona. Utilizada en este tutorial.
Para más información de cada tipo de replicación en el siguiente enlace: http://www.drbd.org/users-guide/s-replication-protocols.html
- Heartbeat
Es un dominio que proporciona servicios de infraestructura de cluster (comunicación y pertenencia) a sus clientes. Esto permite a los clientes tener conocimiento de la presencia (o desaparición) de los procesos en otras maquinas e intercambiar fácilmente mensajes entre ellos. Para resultar útil a los usuarios el dominio HEARTBEAT necesita emplearse en combinación con un gestor de recursos del cluster (cluster resource manager (CRM)) el cual posee la tarea de iniciar y parar los servicios (Direcciones IP, servidores web...) a los cuales el cluster aportará alta disponibilidad. Pacemaker es el gestor de recursos de cluster preferido para los clusters basados en Heartbeat.
Se necesitan dos servidores o máquinas de similares características (tanto en las arquitecturas de dichos servidores y en sus sistemas operativos). En ambas es necesario tener una partición sin montar y sin formatear que esta será utilizada para el DRBD. La capacidad de almacenamiento reservado en estas particiones permitirá almacenar como máximo la capacidad de la partición más chica.
Además se utilizara un Switch y una tercera maquina que será utilizada como cliente y hará uso de los servidores. La topología utilizada para este tutorial es la siguiente:

Hardware utilizado:· 2 maquinas como servidores con sistema operativo Debian
· Un Switch
· Cables UTP
· 1 maquina cliente para la conexión a la base de datos
· Interfaces usb Lan Ethernet
Instalación y configuración de DRBD
1. Procederemos inicialmente a la instalación de los paquetes necesarios para la configuración del Heartbeat
# sudoapt-getinstall drbd8-utils build-essential libreadline6- dev zlib1g-dev
2. Primero vamos a guardar una copia del archivo de configuración original:
# mv /etc/drbd.con /etc/drbd_backup.conf
3. Ahora procederemos a la configuración de dicho archivo:

4. La primera línea de código hace referencia a una encuesta en la cual drbd nos invita a participar y la segunda línea (common) la velocidad de sincronización entre las dos maquinas.
5. De igual manera también denominamos el nombre de recurso (resource pg) en donde un recurso lo podemos definir como término colectivo pero que hace una referencia en particular al conjunto de información que se va a replicar.
6. Declaramos que utilizaremos un método de replicación C (protocol c), en el cual la replicación se dará como completa cuando en ambas maquinas se actualicen los datos.
7. Luego también declaramos el tiempo de espera para la sincronizaion.
8. De igual manera también se declaran los nodos que participaran en el proceso DRBD los cuales cederán el recurso cuando uno se encuentre bajo o fuera de línea. Junto a estos nodos internamente se le declaran:
- La unidad lógica del drbd que se va a crear (/dev/drbd0).
- La partición sin formato en el cual se va montar (en nuestro caso /dev/sda4).
- La dirección IP por medio de la cual se cederán recuro.
- La creación de meta-data correspondiente a la partición lógica que se realizara más adelante.
9. Recordar que este archivo de configuración debe de estar presente en ambas maquinas tanto en la primaria como en la secundaria
10. Una vez realizada correctamente la configuración anterior en ambos nodos procederemos a colorcarnos las respectivas direcciones IP´s para poder iniciar la sincronización del DRBD
# Ifconfig eth1 10.0.0.3/24 up (nodo secundario)11. Ahora iniciamos el DRBD:
·












Referencias

Y observaremos un error al tratar de inicializar el drbd, la causa de este error es que aun no hemos creado la meta-data del recurso que va a compartir.
12. Creamos la meta-data de la siguiente forma:

Mediante el comando drbdadm (este comando permite usar comando para manipular drbd0) create-md pg (pg es el nombre del recurso declarado anteriormente en el archivo drbd.conf) nos permite crear la meta-data del dispositivo lógico drbd0 y el recurso. Recordad que estos comandos deben de realizarse en ambos nodos
13. El paso siguiente es inicializar de nuevo el drbd, el cual no debería de darnos ningún tipo de error.

Podemos ver el estado de la sincronización por medio del comando cat /proc/drbd :

Como podemos ver ya se encuentran conectados pero aun no listos para realizar la replicación o intercambiarse el recurso para ello necesitamos definir un nodo primario y darle formato a la partición que se va a replicar.
14. Ahora es necesario establecer el nodo primario del cluster. Para este ejemplo elegimos absdeb como servidor primario por lo que solo en ésta máquina ejecutamos el siguiente comando, luego damos formato a la partición compartida y montamos la partición:
# sudo drbdadm -- --overwrite-data-of-peer primaryall
# sudo mkfs.ext4 -j /dev/drbd0
# sudo mount -t ext4 /dev/drbd0 /data (carpeta definida en postgresql para nuestro caso la carpeta data)
Y con esto iniciara la sincronización:

Una vez finalizado la sincronización y completada de forma satisfactoria se mostrara algo como lo siguiente:

Como se podrá ver el estado (cs:Connected) se encuentra estable o conectado, estadefinido el nodo primario y secundario y se encuentran listos para la replicación o copiar datos(uptodate/uptodate).
Instalación y Configuración de Heartbeat
1. Procedemos a la instalación de Heartbeat desde los repositorios con el siguiente comando:
# sudo apt-get install Heartbeat
2. En el nodo primario copiamos los archivos de configuración de ejemplo o simplemente creamos archivos nuevos:
# cp /usr/share/doc/heartbeat/authkeys /etc/ha.d/
# cp /usr/share/doc/heartbeat/ha.cf.gz /etc/ha.d/
# cp /usr/share/doc/heartbeat/haresources.gz /etc/ha.d/
# gzip -d ha.cf.gz
# gzip -d haresources.gz
3. Ahora procederemos a la configuración del archivo ha.cf

Esta fue la configuración realizada para nuestro escenario se muestra un comentario al lado de cada comando, el initdead que es el único que no se alcanza a ver es el tiempo se que esperan para cuando ambos nodos no se inician al mismo tiempo, es el tiempo que esperan para iniciar el proceso.
4. Finalmente debemos modificar el archivo haresources. Ahí declaramos los servicios que queremos monitorear y que deben estar siempre disponibles. En cuanto caiga una máquina, la otra tomará el control levantando los servicios monitoreados y tomando la IP Virtual. Dentro de haresources ingresamos:

Les voy a explicar que significa cada parte de este archivo. En primer lugar definimos cuál va a ser el nodo principal en este caso asbdeb. IPaddr::10.0.0.1 es el script que asigna la IP virtual que tendrá el cluster y el cual será el punto de acceso,también la podríamos llamar un ip flotante que será la que el Heartbeat asigne cuando una maquina caiga.
Con drbddisk::pg le decimos que recurso DRBD queremos brindar, luego con Filesystem::/dev/drbd0::/opt/postgresql::ext4::defaults montamos el dispositivo virtual drbd0 en la carpeta /opt/postgresql y por último decimos que arranque o inicie postgresql.
5. En indispensable copiar el archivo de arranque de PostgreSQL a /etc/ha.d/resources.d y modificar la variable de entorno PGDATA de dicho script para que apunte a la carpeta /opt/postgresql/data que es el lugar donde van a residir las bases de dato y al mismo tiempo otorgar los permisos necesarios:
#cp postgresql-9.x.x.x/contrib/start-scripts/linux /etc/ha.d/ resources.d/postgresql
# chmod +x /etc/ha.d/resources.d/postgresql

6. Luego copiamos los archivos de configuración a todos los nodos o realizamos las mismas configuraciones.
Instalación y configuracion del PostgreSQL acceso remoto
1. La instalación de PostgreSQL será a través de la compilación del código fuente porque debemos hacer algunas modificaciones a la variable pg_ctl para que todo funcione correctamente. Descargue el código fuente del siguiente enlace: http://www.postgresql.org/download/
2. Luego de bajar los fuentes del PostgreSQL descomprimimos, y modificamos el código de la aplicación pg_ctl, el archivo fuente de esta aplicación esta en postgresql-8.X.XX/src/bin/pg_ctl/ y se llama pg_ctl.c.
3. Una vez ubicado esta aplicación buscamos la leyenda “no server running” dentro del código y reemplazamos la palabra “running” por cualquier otra.
Esto tiene una explicación y es que Heartbeat verifica si un servicio está corriendo o no buscando la cadena “running” u “ok” al pedir su status, entonces cuando heartbeat le pregunta a PostgreSQL si está ejecutándose correctamente él responde “no server running” y heartbeat supone que todo está bien aunque realmente no sea así.
4. Con la partición montada en la maquina primaria crearemos la ubicación de Postgres dentro de ella con:
# Mkdir /opt/postgresql/data
5. Le asignamos permisos al directorio para que pertenezca al usuario “postgres”
# Chown postgres.postgres –R /opt/postgresql/data
6. Como usuario “postgres” inicializamos los datos de Postgres
# sudo su postgres
# /usr/local/pqsql/bin/initdb –D /opt/postgresql/data
7. A continuación modificamos un par de archivos para permitir el acceso remoto a la base de datos; el primero de estos seria /opt/postgresql/data/postgresql.conf

Modificamos la línea de listen_addresses igualándola a “*” para que escuche en cualquier interfaz de las que el servidor tiene disponibles.
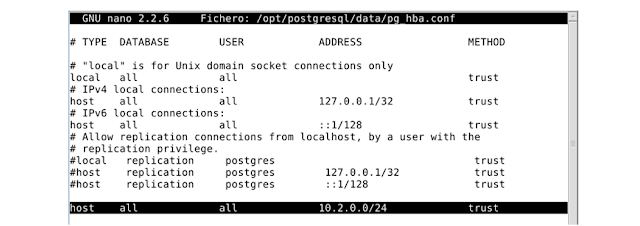
8.El otro archivo a modificar será /opt/postgresql/data/pg_hba. conf y agregamos al final de este la siguiente línea:
Host all all 10.2.0.0/24 trust

Con la línea anterior indicamos a Postgres que permita al bloque de direcciones 10.2.0.0/24 que acceda a cualquier base de datos con cualquier usuario en el servidor. Recordad que estos pasos se aplican solo para la maquina primaria.
Pruebas de del Escenario
1. Una vez realizado correctamente la configuraciones anteriores tanto para Heartbeat y drbd e inicializar el motor PostgreSQL, haber definido el tanto el nodo primario y secundario procedemos a la iniciación de Heartbeat y el servicio DRBD en ambos servidores, PostgreSQL solo en la maquina primaria:
# /etc/init.d/Heartbeat start
# /etc/ini.d/drbd start
# /etc/ha.d/resources.d/postgresql start
2. Una vez inicializado el PostgreSQL en la maquina primaria procedemos crear la base de datos y empezar a crear las tablas, índices, vistas, etc., desde cero.
3. Luego para probar que se estén replicando correctamente los datos, en el nodo secundario ejecutamos el comando “watch cat /proc/drbd” mientras que en el nodo principal bajamos el servicio de hearbeat. Antes de bajar el servicio en el nodo secundario deberíamos tener la siguiente salida en la maquina primaria:

4. Luego bajamos a Heartbeat en la maquina primaria
# /etc/init.d/Heartbeat stop
5. Ahora bien una vez detenido el Heartbeat en la maquina primara, en nuestro servidor secundario deberíamos de ver algo similar a la captura anterior pero con la diferencia que ahora nuestro servidor secundario será primario:

Video de Demostración
Referencias
Documentacion de implementación y comandos DRBD
Documentacion de implementación e instalación de Heartbeat
Documentacion de PostgreSQL
Documentacion de Cluster con PostgreSQL
No hay comentarios:
Publicar un comentario